Table of contents
We covered the UX mental models and architecture for fixing a product signup flow in the last post. Let’s talk about the two remaining models in the UX flow today: (a) context aware guidance using a large language model, and (b) creating a natural language driven signup.
Here are the all the posts in this series:
- Understanding signup flows
- Fixing product signups
- Language models in signup (this post)
- Lessons in customer validation
A quick recap of the UX mental model before we start with Models 2 and 3.
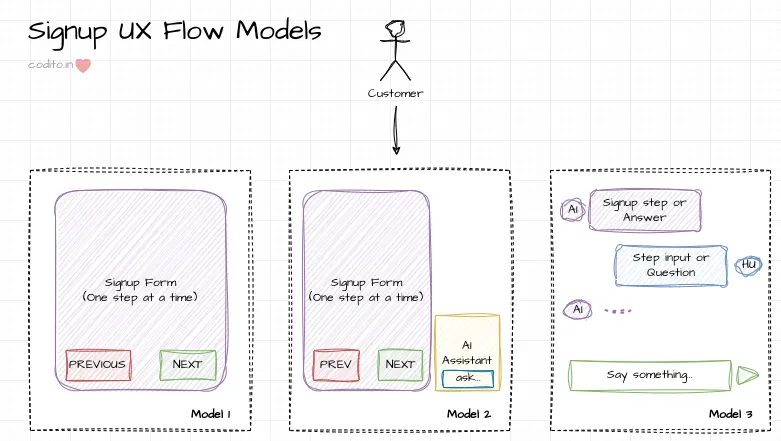
Model 2: Contextual guidance
We have a chat assistant running side by side (sidecar) of the signup flow. It supports three scenarios:
- Help decide a product plan using natural language conversation. E.g., agent asks questions to learn customer preference and then recommend a suitable plan
- Answer any questions related to feature availability in a plan, or compare two plans. E.g., does Plan A support feature X?
- Provide guidance on using a feature. E.g., how do I use X?

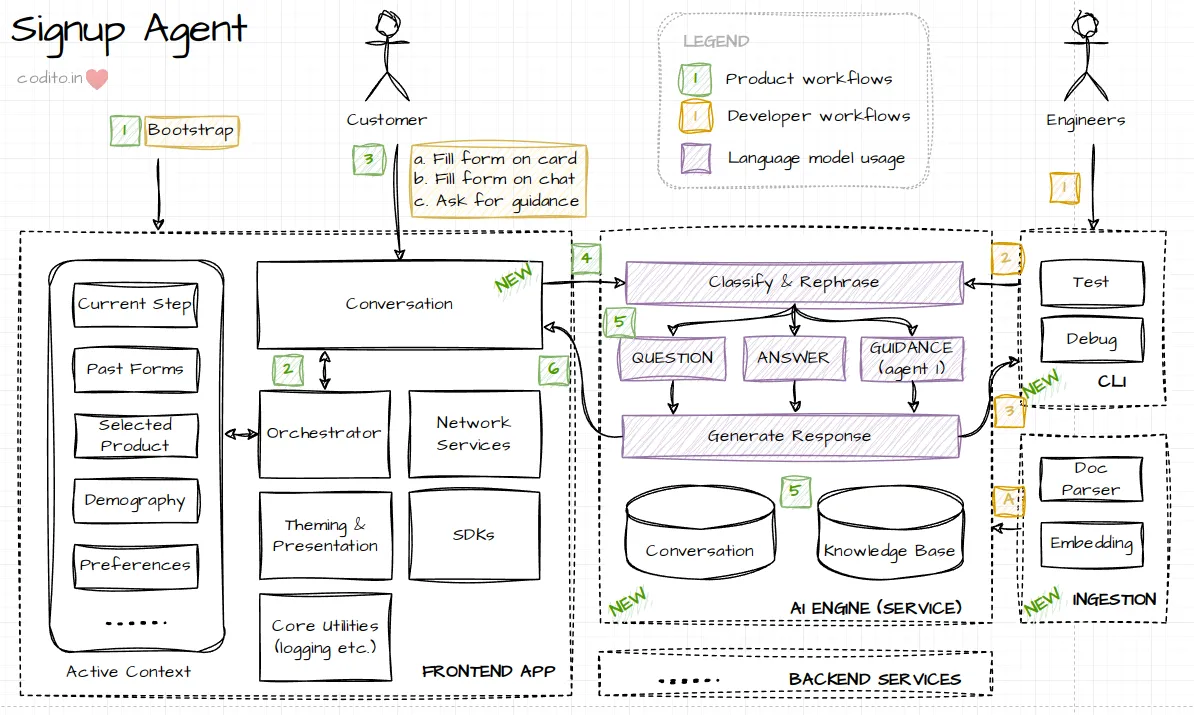
Data flow
-
Customer (she/her) sees one form after another on the web app. This follows the architecture in last post. Orchestrator decides which form to show, each form renders itself and handles customer inputs.
-
She brings up the chat assistant and asks a question. Chat sidecar component retrieves the current context from Signup flow including active form, selected product, etc.
-
User input (query) is first classified and rephrased with LLM.
-
Classification determines which child flow to invoke. E.g., recommend a plan, question about plan & feature, or a usage related question.
-
Rephrase is essential to preserve context for child workflows. E.g., query
How can I configure it?should get rephrased toUser is searching for instructions to configure feature X in product P. This requires the short term conversation context.
-
-
Now we execute the child workflow. Next sections will dive deeper into these flows.
Mental model
Chat Assistant (sidecar) is a reactive flow. User will drive the conversation when they deem necessary.
Option 1: the user query is a “question”, e.g., tell me about product, tell me how to use, or will it work for me? This category should also cater to non-contextual questions like “what’s the weather?” etc.
Option 2: the user query is a statement, and possibly we can derive some information for recommending or helping them later. Again this can be contextual or irrelevant, e.g., I need XYZ for doing task T vs I am wearing a pink t-shirt.
The engine needs to have a good way to deal with irrelevant question or information. It must nudge the customer in a friendly tone about what or how it can help. Let’s call this our fallback prompt.
Relevant question and statements will have different prompts to understand the input and generate answer or ask followup questions.
In summary, each request is one or more prompts executed based on certain logic. A chain of prompts as some popular frameworks call it.
We supplemented the knowledge of the LLM with in-prompt structured data, external knowledge base/vector store and a short-term conversation memory stored in a relational store.
Product selection
Our goal is to provide a personalized recommendation for the Customer based on their preferences. If we don’t have enough information, we’ll ask questions. Otherwise, generate a recommendation.
Here’s the algorithm.
-
Do we know enough to recommend? Yes.
-
We present the information to LLM and ask for a recommendation.
- Form Context: user inputs and preferences in the various forms.
- Conversation Context: discussion part of the current chat.
- Jobs To Be Done (JTBD) matrix: various “user needs” captured from the questions.
- Rules: choose the cheapest and simplest plan that covers all user needs.
-
Challenge: how do you decide when to recommend?
- We maintained a state (JTBD matrix). Rows are the goals and columns are the tasks to achieve the goal. A “yes” for the cell indicates user preference.
- If 50% of the rows are covered, the engine shares a recommendation.
-
Challenge: what if user denies our recommendation or shares more requirements?
- Such requirements are automatically captured as part of Conversation Context provided to the recommendation engine.
- New requirements in user query are evaluated if they’re matching any of the JTBD matrix; we update the state.
-
-
No, we need more information.
-
Challenge: find a question to ask.
- Get a row with all empty cells in the JTBD matrix, ask the LLM to generate a question.
-
Associate the next user statement with the last question and update the matrix state.
-
Both question generation and answer parsing prompts here used semantic similarity. We further instructed the LLM to always generate response in a JSON or similar structured format.
Product guidance
We used an inline (i.e., inside prompt) marketing/product features structured dataset to answer product plan comparison and feature related guidance. Maintenance of the dataset just involves updating the prompt.
For detailed guidance questions, we used the Retrieval Augmented Generation approach. Here’s the algorithm.
Knowledge base preparation is done via a command line app.
- Use a documentation dataset (markdown formatted), parse and create chunks of phrases. Use a semantic embedding model to generate phrase vectors and store them in a FAISS vector index.
- Document to Phrase mapping is stored in a Sqlite database.
Retrieval Augmented Generation
- Get the rephrased and English translated query (necessary for multilingual input).
- Find the semantically related phrases for given query from FAISS index.
- Order the phrases by their appearance order in the documents.
- Provide list of phrases, user query and ask LLM to generate an answer.
Model 3: Conversations everywhere
Driving the entire signup process through chat required the Agent to be on the front seat. It must be proactive. We brought the concepts of Conversation and Message to signup.
Mental model
A conversation consists of messages. Each message can play two roles. Either it asks the Customer for some input, i.e., seek inputs for the currently active form. Or, the message could answer some question from the Customer. Being proactive implies the Agent must try to bring back a conversation on track. It should nudge the Customer to complete a step. We extended the Orchestrator to track conversation and render a Step as a Card (message) for the user.
Unlike traditional signups, the conversational model provides user access to entire history of their inputs for each of the previous forms. This required every Step to now define an “inactive” and an “active” card view. Previous forms render as “inactive” card with a readonly view of user response. User can only interact with the “active” card.
Active cards allowed input both interactively and on the chat input using natural language. Further form can decide if its card will be interactive only. E.g., for payment or account creation forms chat input was disabled for security reasons.
A critical challenge was ensuring that conversation stays on track. This is hard since we allowed guidance on the same conversation (trying to simulate a Sales Advisor role). E.g., user can ask a question back when the AI agent is asking them for filling a form. We need to understand the context change, let the Q&A thread proceed, finally remind the user to fill the current form. We solved this with a disambiguation/classification step in LLM flow: given a conversation context and user query, identify if the user input is an “answer to previous question” or “a new question”.
Question and Answer on a form
To extend the form for conversation interface, we created a Step Description Language. Every form can describe the question and answers in a DSL. A form has one or more questions. And a question can be single choice, multiple choice or text input. Based on this we built the generic Card rendering for “interactive” inputs, and a natural language (NL) engine for text based answers to the form.
We allowed the form to decide if it needs to render a Card for the question (e.g., payment form), or let the NL engine ask questions for the form (e.g., account details form). Card rendering is straightforward.
Generating questions is hard because of the state management, i.e., keeping track questions already asked, questions with invalid values, questions that can be skipped etc. We used a LLM prompt that understands the Card DSL and the context. We extensively relied on the CoT paradigm to force the LLM to identify the right question to ask.
Parsing NL answers had its own set of challenges. We need to identify the right question first. E.g., agent asks “What’s your first name?” and user responds with “My full name is John Doe”. Will you ask for the last name? No, the prompt must ensure both fields are filled. Second, we supported lightweight validation for email, or phone number in the prompt. This was hard because of country specific differences, solvable through dynamic rules injection in the prompt.
We learned that few shot prompting doesn’t work well when the examples fall in the same domain as the form; they unnecessarily create bias. We resorted to doing few shot prompting on a complete unrelated domain/question set. This helped teach rules to the LLM without corrupting its knowledge of the domain. E.g., give examples of filling a form around Geography, like which is the largest planet etc. instead of signup examples.
Composing over other engines
If the user input is a “question on relevant topic”, we handed it over the Guidance engine built in Model 2. It will further identify the child workflow on plan selection, plan Q&A or product usage Q&A to generate a response. This effectively meant Model 2 is a tool used by Model 3.
Now, the new challenge before us was to ensure coherence in the discussion and also control the flow. We cannot let the Guidance engine take over the conversation, nor can we let the Signup agent to go passive and not ask any questions for the current form.
One’s good, two’s crowd. Let’s bring a third, to arbitrate 😀
The third agent has only one job - to ensure that the overall conversation stays on track. As input, it takes the “question” from signup agent, “answer” from guidance agent, and user’s question. Do some magic and generate an AI response that both answers the user question and nudges them to answer the question from previous parallel thread.
Another challenge was sharing the short-term memory across agents. We decided to keep the Guidance and Signup agent’s memories encapsulated within their own domains. This simplified our algorithm and also didn’t allow one agent’s thoughts to confuse the other. Arbitration agent was completely stateless with only a restricted view into last exchanges of both the above agents.
Closing notes
Few things to ponder for the next time I build such a system.
- Think ReACT. In our model, reasoning was not really separate. We built control flow statements through various prompts. Maybe it can be offloaded to a LLM orchestrator?
- What’s the difference between an Agent and a Tool? Should the Guidance Agent be an agent? May be not. It should be a tool. Arbitration agent can just be a step in the elaborate plan created by the “one” agent.
- Debugging and testing: we built a CLI tool to debug and test the prompts by invoking the same interfaces as the actual program. This helped us iterate rapidly and do in-depth finetuning of prompts. I will carry this for the next project ❤️
Here’s a hypothesis for the next few years.
Like a database engine, we will build abstractions to generalize the core paradigms for LLMs. E.g., plan, query optimization/rewrite and execute. Eventually, LLM programming will reduce to just developing extensions (or skills, tools, whatever you have).
This is not necessarily a bad thing. It is the only way to massively increase adoption of systems. A lot of us will write the extensions, fewer will build the abstractions and fewer still will optimize the actual LLM inference. You see the pyramid?
That’s all for this post.
In the final part of this series, we will cover the lessons learned from running a customer validation in India. Thank you for reading!